億級數據湖統一存儲技術實踐
隨著企業數據量的指數級增長,傳統的分散式數據存儲架構已難以滿足大規模數據處理與分析的需求。億級數據湖統一存儲技術應運而生,旨在構建一個集中式、可擴展且統一的數據存儲平臺,以支持多樣化的數據處理任務。本文將探討億級數據湖的技術實踐,并重點介紹數據處理和存儲支持服務的關鍵方面。
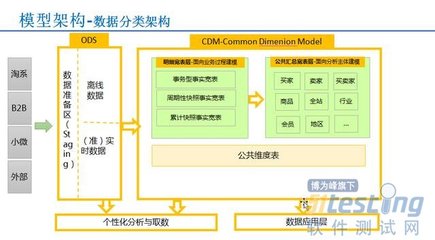
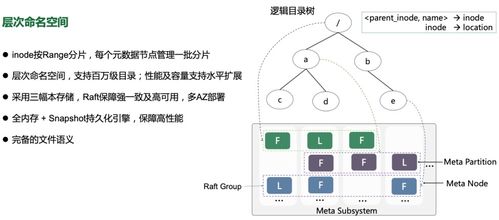
億級數據湖的核心在于統一存儲架構。通過采用對象存儲(如Amazon S3、阿里云OSS)或分布式文件系統(如HDFS),數據湖能夠整合結構化和非結構化數據,打破數據孤島。這種架構支持PB級甚至EB級數據的存儲,同時通過元數據管理實現數據的可發現性和治理。在實踐中,企業需設計靈活的數據分區和索引策略,例如按日期、業務域或數據類型進行組織,以優化查詢性能。結合數據壓縮和分層存儲(如熱、溫、冷數據分層),可以有效控制存儲成本,確保高性價比的擴展性。
數據處理是數據湖生態的關鍵環節。借助大數據處理框架如Apache Spark、Flink或Hadoop,數據湖支持批處理和實時流處理,實現從原始數據到洞察的快速轉換。在實踐中,企業可以采用ETL(提取、轉換、加載)或ELT(提取、加載、轉換)流程,將數據清洗、轉換和聚合任務整合到數據湖中。例如,通過Spark作業處理海量日志數據,生成聚合指標,或使用Flink進行實時事件處理,以支持即時決策。為了提升效率,數據湖常集成數據目錄工具(如Apache Atlas)和數據質量監控機制,確保數據的一致性和可靠性。
存儲支持服務則涵蓋數據安全、備份和訪問控制等方面。在億級數據湖中,數據安全至關重要,需實施加密(如AES-256)、訪問策略(如基于角色的訪問控制)和審計日志,防止未授權訪問和數據泄露。同時,定期備份和災難恢復計劃(如多區域復制)可保障數據的高可用性。存儲支持服務還包括性能優化,例如通過緩存機制(如Alluxio)加速數據讀取,或利用數據湖查詢引擎(如Presto、Trino)提升交互式分析速度。
億級數據湖統一存儲技術實踐不僅依賴于先進的存儲架構和數據處理工具,還需要全面的支持服務來確保數據的安全性、可靠性和高效性。通過合理設計和管理,企業可以構建一個強大的數據基礎,驅動業務創新和智能化轉型。未來,隨著AI和云原生技術的發展,數據湖將進一步演進,提供更智能的數據管理和自動化服務。
如若轉載,請注明出處:http://www.ljrce.cn/product/33.html
更新時間:2026-01-21 01:11:39