專訪QQ大數據團隊 分布式計算系統開發與數據處理存儲支持服務
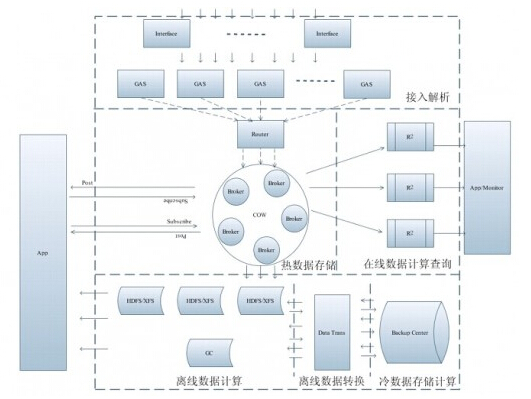
隨著互聯網數據的指數級增長,分布式計算系統已成為現代數據處理架構的核心支柱。近日,我們有幸專訪了QQ大數據團隊,圍繞其分布式計算系統開發實踐、數據處理及存儲支持服務進行了深度交流。
作為騰訊旗下重要產品的支撐力量,QQ大數據團隊見證了海量用戶行為的處理需求——從億級用戶的在線狀態同步,到聊天記錄的實時分析與歷史查詢,再到個性化推薦與安全風控。團隊負責人李明指出:『我們的系統每日處理PB級數據,需確保毫秒級響應與99.99%的可用性。這背后是一套自研的分布式計算框架「QQDataFlow」,支持流批一體計算,并深度整合了機器學習管道。』
在數據處理層面,團隊通過分層架構實現高效治理:原始數據經 Kafka 集群接入后,由 Flink 進行實時清洗與聚合;批處理任務則通過 Spark 執行復雜指標計算。值得注意的是,團隊創新性地引入了「動態資源調度算法」,能根據業務峰谷自動調整計算節點,資源利用率提升40%。數據工程師王華補充:『我們為內部業務提供了統一數據服務門戶,支持SQL即席查詢與可視化報表生成,將數據分析門檻降至極低。』
存儲體系的搭建同樣彰顯匠心。團隊采用混合存儲策略——熱數據存于自研分布式數據庫 TDSQL,冷數據歸檔至騰訊云對象存儲。存儲專家張磊詳解其設計哲學:『我們為消息記錄設計了冷熱分離索引,熱數據保證亞秒級查詢,同時通過壓縮算法將冷數據存儲成本降低70%。所有存儲節點均實現跨地域容災,數據持久性達99.9999999999%。』
談及未來規劃,團隊正聚焦三大方向:其一是推進計算存儲分離架構,實現更極致的彈性擴縮容;其二是構建智能數據湖,打通業務孤島并強化數據血緣追溯;其三是探索聯邦學習在隱私保護場景的應用,讓數據『可用不可見』。李明總結道:『分布式系統的本質是平衡藝術——在性能、成本與易用性間尋找最優解。我們將持續開放技術能力,為行業提供可復用的數據處理范式。』
這場專訪揭示了一個真理:在數據洪流的時代,唯有將分布式技術與業務洞察深度融合,方能為用戶創造流暢如水的數字體驗。QQ大數據團隊的實踐,正為行業樹立著技術賦能業務的鮮活樣本。
如若轉載,請注明出處:http://www.ljrce.cn/product/25.html
更新時間:2026-01-21 22:19:07